e3 Kenneth Laudon 管理信息系統 v11
6.2 數據管理的數據庫方法
數據庫技術可以解決傳統文件系統所帶來的諸多問題。可以將數據庫嚴格定義為:數據庫是經過組織的數據集,通過對數據的集中管理控制數據冗餘,可以有效支持多個應用程序。數據不再分散儲存在分散的文件裡,在用戶看來是儲存在同一個位置。一個數據庫為多個程序服務。例如,企業可以把原來分散在多個系統和多個文件中的個人資料、工資單數據和員工福利資料等,建立起一個統一的人力資源數據庫。
6.2.1 數據庫管理系統
數據庫管理系統 (DBMS)是數據集中、有效管理並通過軟件程序訪問數據的軟件。數據庫管理系統是應用程序與數據文件之間的接口。當應用程序需要調用數據時,例如總支出,DBMS查找數據並傳送給應用程序。通過傳統的數據文件,程序員需要定義數據的大小和格式並且告訴計算機數據所處的位置。
DBMS通過區分數據的物理視圖(physical view)和邏輯視圖(logical view),使得用戶不需要了解數據以怎樣方式存儲在哪裡。邏輯視圖以最終用戶所使用的直觀方式來顯示數據,物理視圖則顯示了數據的實際組織形式以及它在物理存儲介質上的結構。
數據管理軟件使得物理數據庫可以應用於不同應用程序所需的不同邏輯視圖。例如,在圖6-4的人力資源數據庫中,一個處理員工福利的專家可能需要員工姓名、社會保障號碼和健康保險。一個員工薪金支付部門的職員可能需要員工姓名、社會保障號碼、總支付金額和淨支付金額。所有這些數據都存儲在一個數據庫中,以便公司管理。
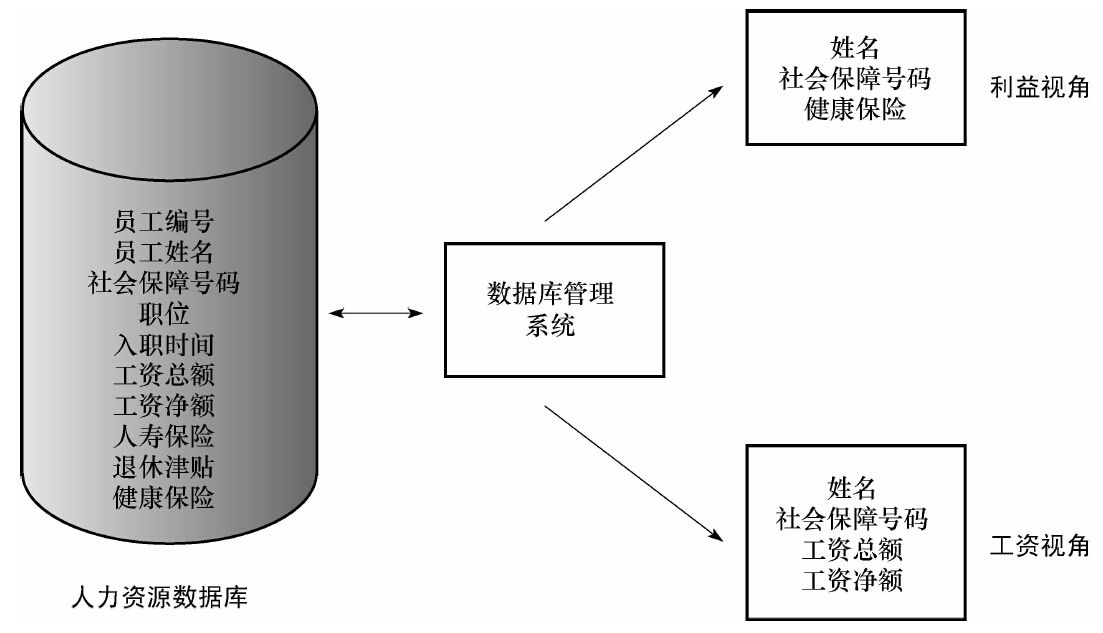
圖6-4 多重視角下的人力資源數據庫
1.DBMS如何解決傳統文件環境帶來的問題
DBMS可以通過對數據的集中管理,避免數據的孤立存儲,進而降低數據冗餘和數據不一致性。雖然DBMS可能不能夠完全消除數據冗餘,但可以對數據冗餘進行有效控制。而且,即使存在數據冗餘,DBMS也可以幫助避免數據的不一致性,因為DBMS可以保證冗餘數據取相同的值。DBMS獨立於應用程序和數據而存在,使數據獨立存在。因而數據的訪問性和可用性大大增加,應用程序的開發和維護費用也大大降低,因為用戶可以在數據庫進行特定的查詢。DBMS使組織可以集中管理、使用數據並保證安全性。
2.關係型DBMS
現代DBMS使用不同的數據庫模型追蹤實體、屬性和關係。在個人電腦、大型計算機和主機上應用最廣泛的數據庫管理系統是關係型DBMS (relational DBMS)。在關係型數據模型中,用二維表格表示數據庫中的數據。這些表格稱為“關係”。每一個表格包括實體中的數據和屬性。微軟Access是一種應用個人計算機系統的關係型DBMS,DB2、Oracle Database和微軟SQL Server是應用在大型主機和中間型計算機的關係型DBMS。MySQL是一個流行的開源DBMS,Oracle Database Lite應用於小型手提計算設備。
圖6-5顯示了供應商和零件的關係。每一個表格都有行和列。每一個獨立的實體的數據元素都表示相應實體的一個屬性。關係型數據庫中的字段也稱為列。對於供應商實體,編號、名稱、地址、城市、州和郵編作為字段存儲在供應商表格中,每一個字段表示供應商實體的一個屬性。
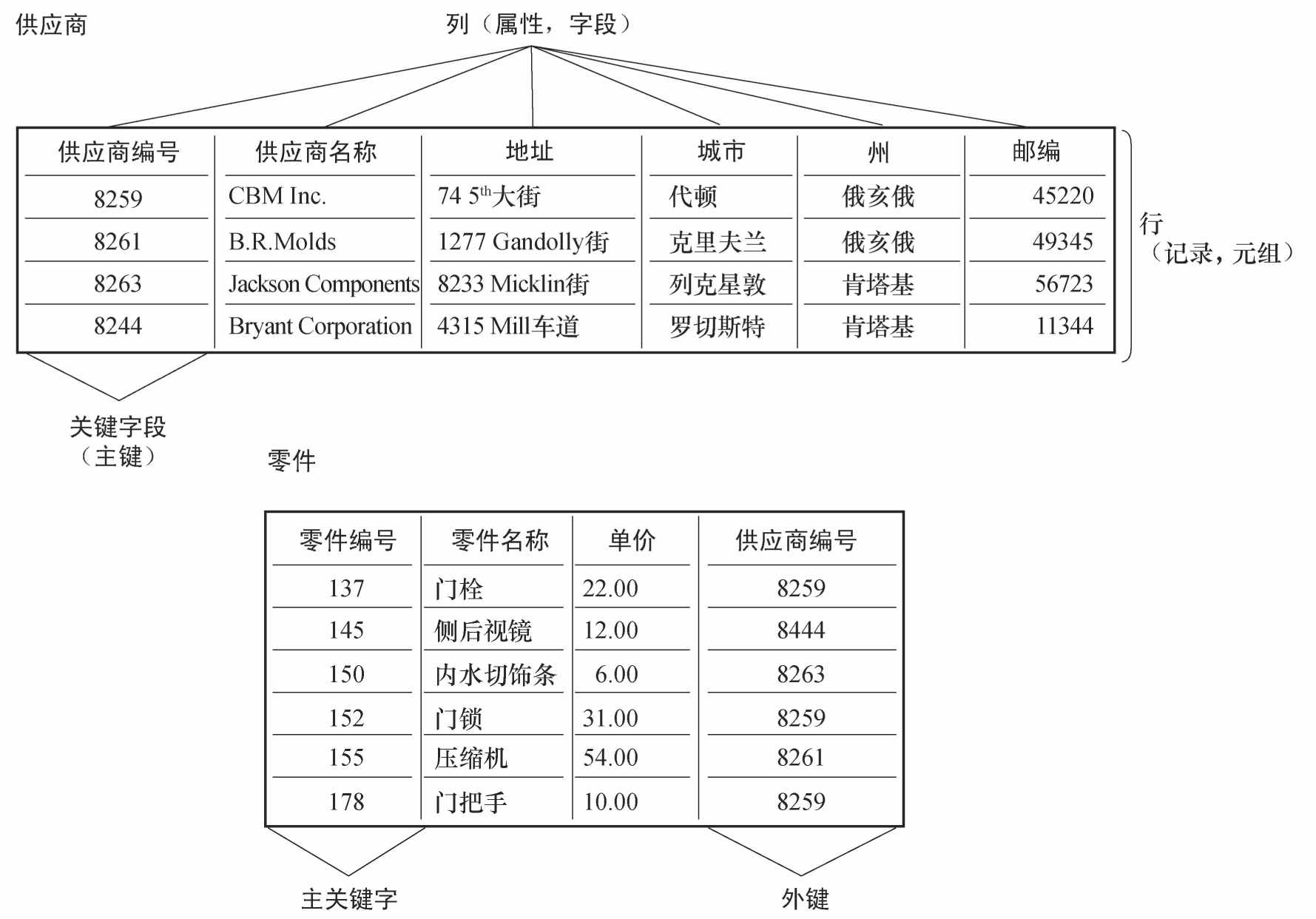
圖6-5 關係型數據庫
供應商編號中的字段標識了每一個記錄,稱為關鍵字段,以便這些記錄可以檢索、更新或排列。每一個關係型數據庫的表格都有一個字段被定義為主鍵。這個關鍵字段標識了每一個存儲在表格中的供應商信息稱為行。行一般表示不同的記錄,或者稱為元組(tuple)。零件實體有單獨的表格。
表格行中的所有信息,並且主鍵不能複製。供應商編號是供應商表格中的主鍵,零件編號是零件表格的主鍵。注意供應商編號同時出現在供應商表格和零件表格中。在供應商表格,供應商編號作為主鍵。當供應商編號字段出現在零件表格中時,它被稱為外鍵 (foreign key),並作為搜索特定零件供應商的檢索字段。
3.關係型數據庫的操作
關聯型數據表格可以通過簡單地組合為用戶提供所需的數據。假設我們想在數據庫中搜索哪個供應商可以為我們提供零件137和零件150。我們需要兩個表格的信息:供應商表格和零件表格。注意這兩個文件共用一組數據元:供應商編號。
一個關聯型數據庫通過三個基本操作生成用戶所需的數據:選擇、連接和投影,如圖6-6所示。選擇操作通過選擇符合要求的記錄組成一個子集,換句話說,選擇操作生成一個符合特定標準的行。在這個例子裡,我們希望從零件表格中選擇零件編號等於137或150的記錄(行)。連接操作將有關聯的表格組合,為用戶在一個表格裡提供更多的有用信息。這裡,我們希望在被縮短的表格中(只包括零件137和零件150)加入供應商表格中的信息生成一個新的表格。
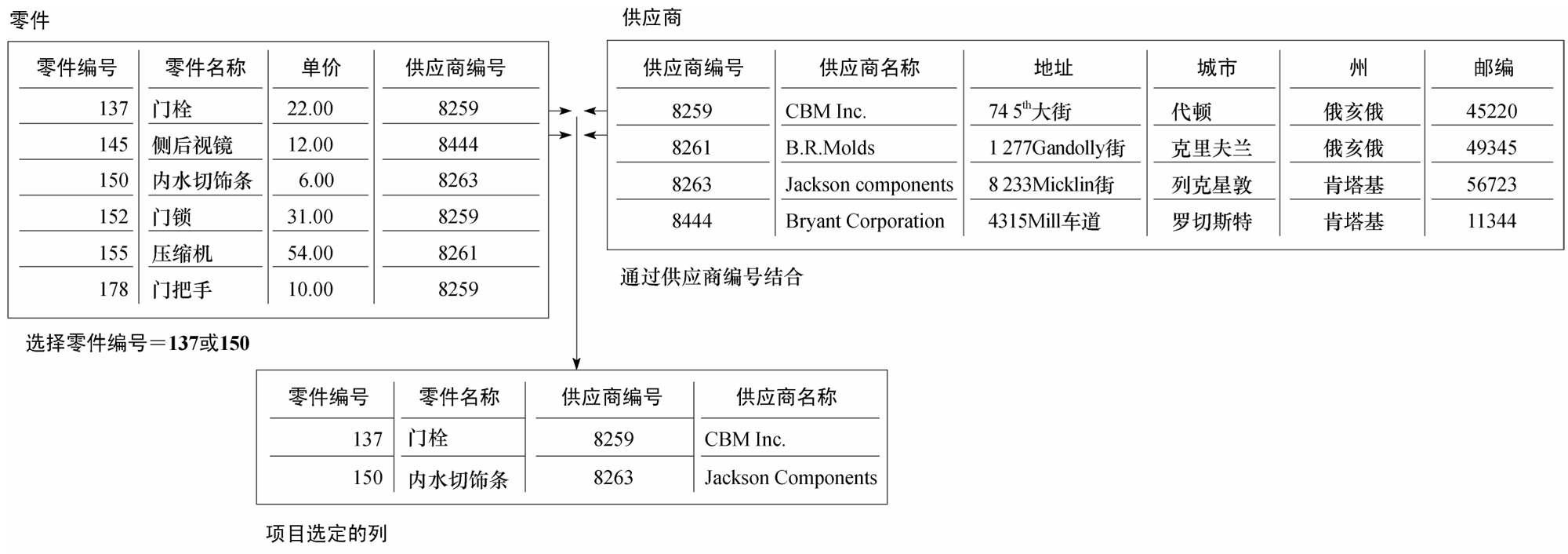
圖 6-6
投影操作創建一個包括列的新的子集,為用戶提供一個只包括所需信息的表格。這裡我們希望生成一個只包括零件編號、零件名稱、供應商編號和供應商名稱。
4.面向對象的數據庫
現在,越來越多的應用程序不僅需要數據庫能夠處理數字和字符,還需要能夠處理繪圖、圖像、照片、聲音和視頻。傳統的DBMS無法很好地處理這些基於圖像或多媒體的數據。關係型數據庫中需要將數據排列成行和列,並不適合應用於圖形或多媒體程序。而面向對象的數據庫更適合這些程序。
面向對象的DBMS (object-oriented DBMS)可以自由地檢索和共享數據。因為可以用於管理各種多媒體數據或Java Applet(廣泛應用於Web應用中),面向對象的數據庫管理系統正變得越來越普及。
雖然面向對象的DBMS相對於關係型DBMS可以存儲更加複雜的信息類型,但是在處理大量數據的速度方面遜色於關係型DBMS。因此,現在出現了一種兼顧了面向對象的DBMS和關係型DBMS兩者優點的混合型DBMS,即對象-關係型DBMS (object-relational DBMS)。
6.2.2 數據庫管理系統的功能
DBMS可以組織、管理和訪問數據庫中的數據。最重要的是數據定義語言、數據字典和數據操縱語言。
DBMS利用數據定義 (data definition)說明數據庫的結構。利用數據定義語言建立數據庫表格並定義每個表格中字段的屬性。這些數據庫相關的信息作為文檔存儲在數據字典中。數據字典 (data dictionary)是一個自動的或手動的存儲數據元的定義和屬性的文檔。
微軟Access有一個可以顯示數據表格中每一個字段的名稱、描述、大小、類型、格式和其他屬性的數據字典(見圖6-7)。大型公司數據庫的數據字典可能包括一些額外的信息,例如用途、所有權(誰負責維護數據)、授權、安全性、業務功能、程序、調用數據元的報告。
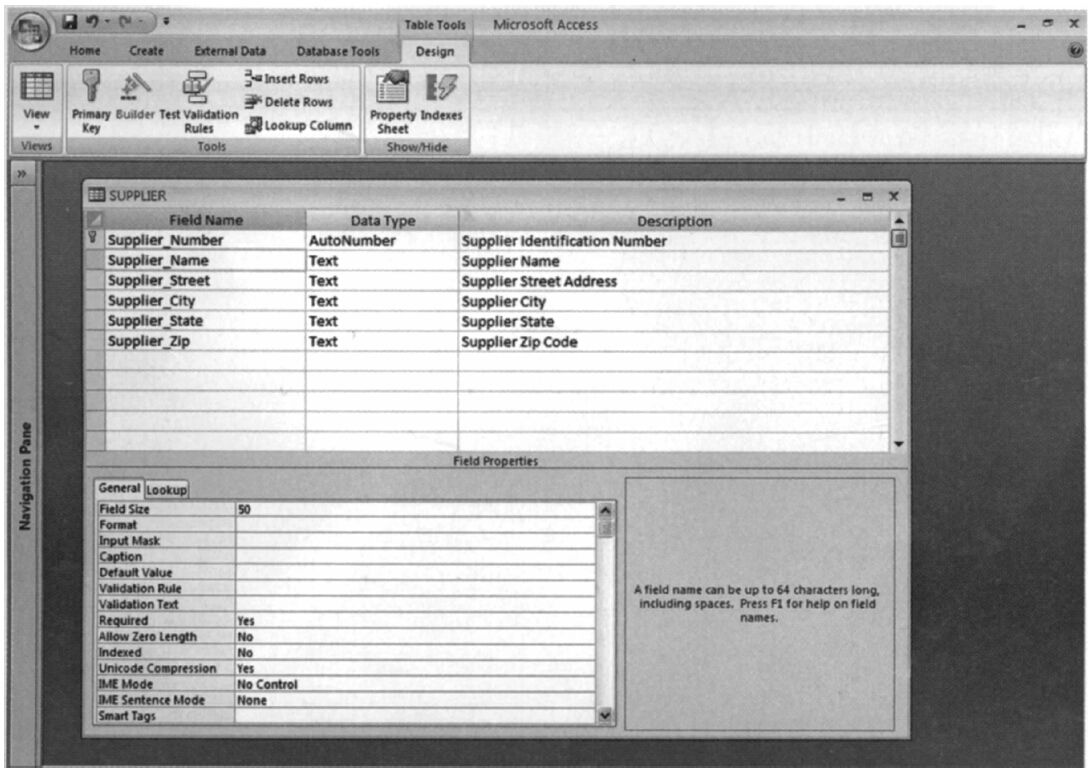
圖6-7 微軟Access數據字典界面
詢問和報告
DBMS包括訪問和操縱數據庫信息的工具。大多數DBMS有一個專門的數據操縱語言 (data manipulating language),用於增加、改變、刪除和檢索數據庫中的數據。這個語言包括一些命令,允許最終用戶和程序員提取符合特定信息或程序要求的數據。現在最為廣泛的數據操縱語言是結構化查詢語言 (structured query language),或簡稱為SQL。圖6-8列舉了可以生成圖6-6的SQL。

圖6-8 SQL實例
大型或中間型計算機DBMS用戶,例如DB2、Oracle或SQL Server,會利用SQL檢索數據庫中的數據。微軟Access也使用SQL,但是提供更加親和使用者的數據庫檢索工具和數據組織工具,生成更加美觀的報告。
在微軟Access中,用戶可以定義檢索的表格和字段,之後Access會選擇符合特定標準的行。這些操作會轉化成SQL命令。圖6-9列舉了微軟檢索工具如何像SQL一樣選擇特定的零件和供應商。
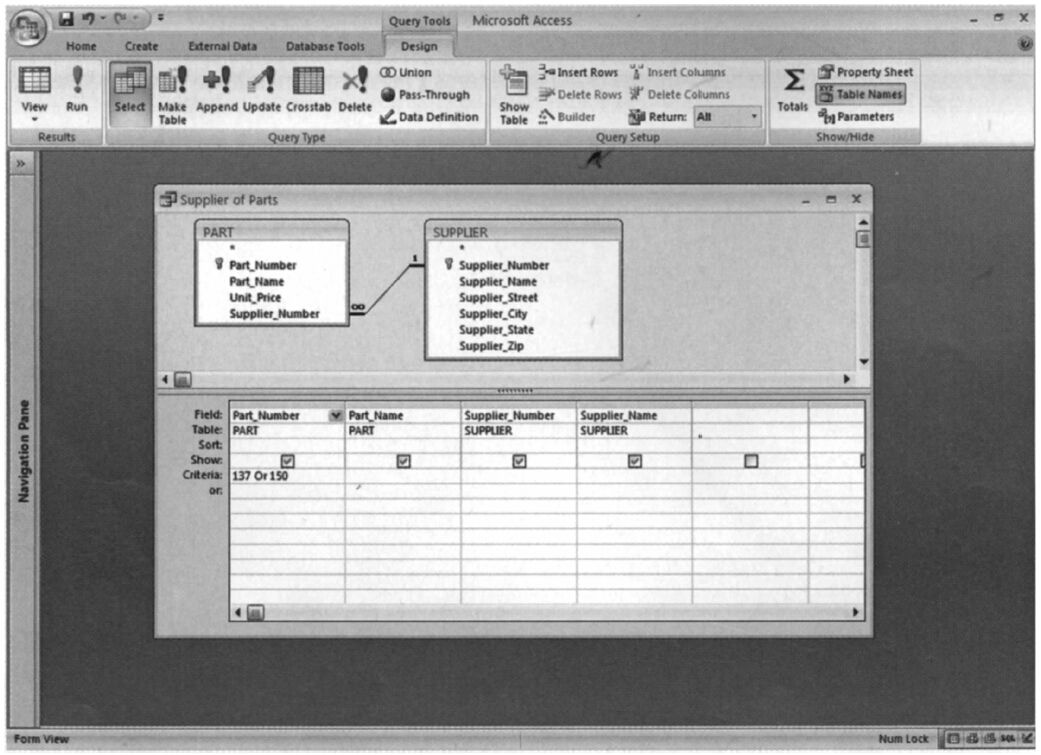
圖6-9 Access實例
微軟Access和其他DBMS都包括生成表格的功能,以便數據可以通過檢索以更結構化、更美觀的形式呈現在用戶面前。Crystal Reports是比較流行的用於公司大型DBMS的報告生成工具,它同樣也可用於微軟Access。Access也可以用來開發桌面系統應用程序,包括數據輸入界面、報告和開發邏輯交易處理工具。
6.2.3 設計數據庫
要創建數據庫環境,首先要了解數據之間的關係、數據的類型和用途,以及組織需要採取的相應變革。建立數據庫之前,首先要經過概念設計和物理設計兩個階段。概念設計(也稱為邏輯設計)是從業務的角度建立一個抽象的數據庫模型,而物理設計是指數據庫如何存儲在直接訪問的存儲設備中。
1.規範化和實體聯繫圖
概念設計描述瞭如何組織數據庫中的數據元,包括確定數據元之間的關係,滿足信息需求的最佳數據元組織方式。概念設計還需要確定冗餘的數據元,以及特定的應用程序所需的數據元組合。數據會被組織、精簡和梳理,直到數據庫中的數據之間的邏輯關係完全呈現出來。
為了有效地建立關係型數據庫模型,需要把複雜的數據組合進行簡化,儘可能減少數據冗餘和多對多的數據聯繫。將複雜的數據組合簡化成小型、穩定和靈活的數據結構的過程稱為規範化 (normalization),如圖6-10和圖6-11所示。

圖6-10 未規範化時的訂單流程
圖6-11 規範化後的訂單表格
關係型數據庫系統利用引用完整性 (referential integrity)原則確保表格之間的關係。當一個表格包括一個指向另一個表格的外鍵,你將不能在表格中加入連帶外鍵的記錄,除非在關聯表格中有相應的記錄。在這一章開始所引用的數據庫中,外鍵供應商編號將零件表格與供應商表格相連。因此我們將不能在零件表格中加入一個新的包括供應商編號為8266的記錄,除非在供應商表格中有相應的供應商編號8266的記錄。換句話說,我們不能在零件表格中增加一個不存在的供應商。
數據庫設計者通常使用實體聯繫圖 (entity-relationship diagram)表示數據模型。圖6-12顯示了實體訂單、零件、條目和供應商。矩形框表示實體,連接矩形框的直線表示實體之間的聯繫。直線末端標註兩條短線的表示一對一關係,直線末端以鳥足符號(Crow’s Foot)標註的表示一對多關係。圖6-9中,“訂單”和“訂貨零件”之間的直線表示一份“訂單”可以包括多個條目(即可以通過一份訂單訂購多種零件,並且每一種零件可以多次訂貨,也可以在一份訂單中訂購多份某種零件)。每一種零件只能有一個供應商,多份該種零件只能由同一個供應商提供。

圖6-12 實體之間的聯繫
需要強調的是,企業如果沒有正確的設定數據模型,系統是不能發揮作用的。如果公司系統利用不準確的、不完整的或者不便檢索的數據運作,也不能發揮應有的作用。瞭解數據的組織結構和在數據庫中的含義也許是你從這門課程學到的最重要的東西。
例如,Famous Footware,一家很知名的連鎖鞋店,在45個州擁有800間分店,由於數據庫不能快速地同步庫存而不能做到“正確的款式在正確的店鋪以正確的價格出售”。公司擁有一個在IBM AS/400中型計算機上運行的與Oracle相關的數據庫,但是數據庫只設計成提供管理報告的單一功能,而不能反映市場變化。管理者不能從報告中得到各家分店的庫存信息。公司針對這個問題建立了一個新的數據庫,優化了銷售和庫存數據,使其便於分析和管理。
2.分佈式數據庫
數據庫設計還要考慮數據如何分佈。信息系統可以設計在一個有中央數據庫的客戶機/服務器(使用單一中央處理器或多處理器)網絡中。數據庫可以分散分佈。分佈式數據庫 (distributed database)存在於多個地點。
主要有兩個方法分佈數據庫(見圖6-13a)。分區數據庫,一部分數據庫在一個地方存儲並維護,另一部分數據庫在另一個地方存儲和維護,每一個地方都有數據為本地服務。中央數據庫批量修改本地文件,通常是在晚上。另一個方法是在地方服務器複製(全部複製)中央數據庫(見圖6-13b)。例如,漢莎航空將其中央主機數據庫更換成複製型數據庫,使調度員可以更快得到信息。任何漢莎航空法蘭克福DBMS上的變動都會自動地在紐約和中國香港被複制。這同樣需要在空閒時間更新中央數據庫。
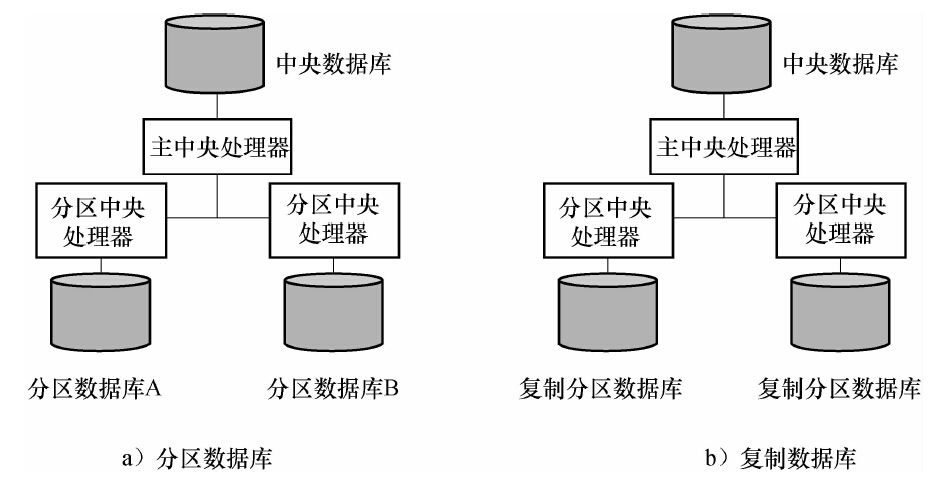
圖6-13 分佈式數據庫
分佈式系統彌補了單一大型數據站點的缺點。提高了對本地用戶的響應能力,並且可以在小型、廉價的計算機上運行。本地數據庫有時和中央數據的標準和定義相背離,或者對於敏感數據的安全性不能保證。數據庫設計者應權衡這些因素來做決定。